小红书图片视频原链寻找
小红书图片视频原链寻找
安卓抓包参考:Android抓包心得
(随便点击的帖子,用于测试)
配置fiddler,显示image
提取链接
1
2
http://sns-img-bd.xhscdn.com/1000g00824fXXXXXXXXXXXXX6t5t82icg170?imageView2/2/w/1080/format/reif/q/90
http://sns-img-bd.xhscdn.com/1000g00824fXXXXXXXXXXXXX6t5t82icg170 # 最终访问
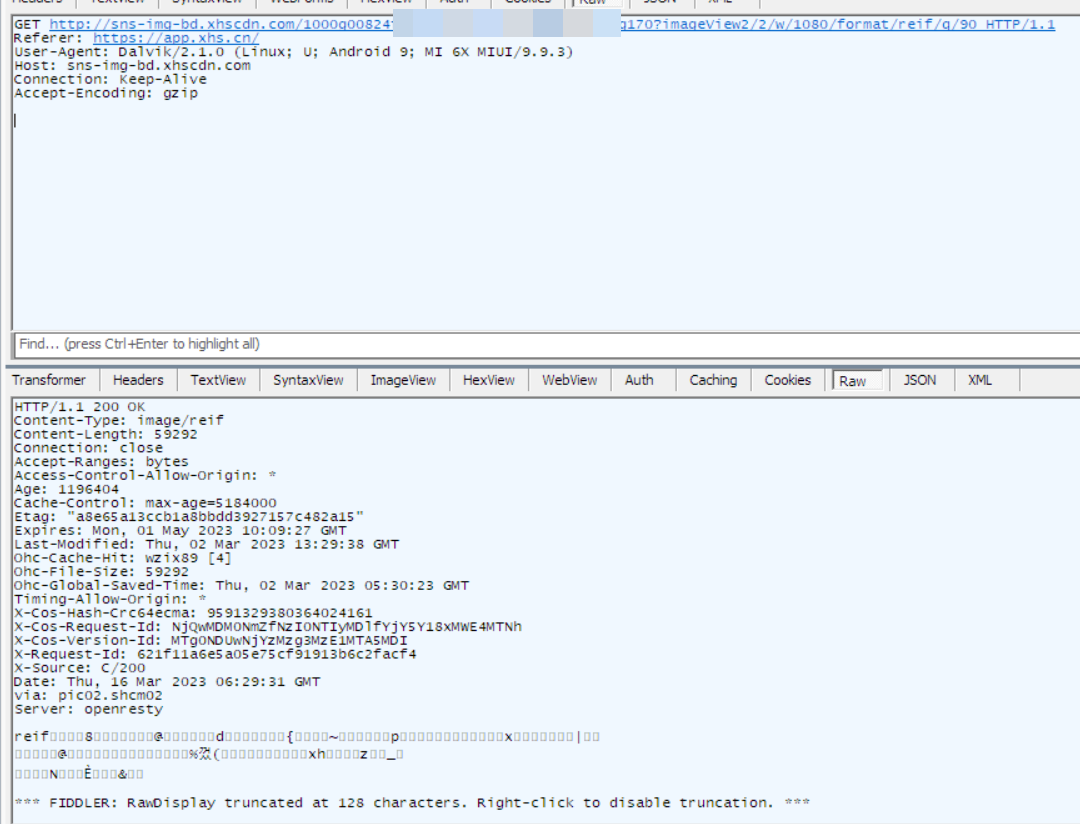
原链 就存在 html 里面,没有什么花头。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
图片类
"imageList": [
{
"fileId": "",
"height": ,
"width": ,
"url": "URL",
"traceId": ""
},
......
视频类
"masterUrl": "URL",
"qualityType": "HD",
"streamDesc": "WM_X264_MP4",
"audioCodec": "aac",
"fps": 30,
"audioDuration": 11911,
"backupUrls": [
"URL",
"URL",
"URL"
],
web_session 和 webid X-T X-S 有关系,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import requests
session = requests.Session()
time_sjc = str(round(time.time() * 1000))
hex_string = ''.join(random.choices('0123456789abcdef', k=32))
headers_sess = {
'Host': 'edith.xiaohongshu.com',
'Cookie': f'webId={hex_string}',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36',
'X-T': '1678954686651',
'X-S': 'O65K0gMpZ2wv0gTLOjUUs6MLsl9lZjVUsl5+Z6TiOlA3',
}
session.post("https://edith.xiaohongshu.com/api/sns/web/v1/login/activate",headers=headers_sess,data='{}')
print(session.cookies.get_dict())
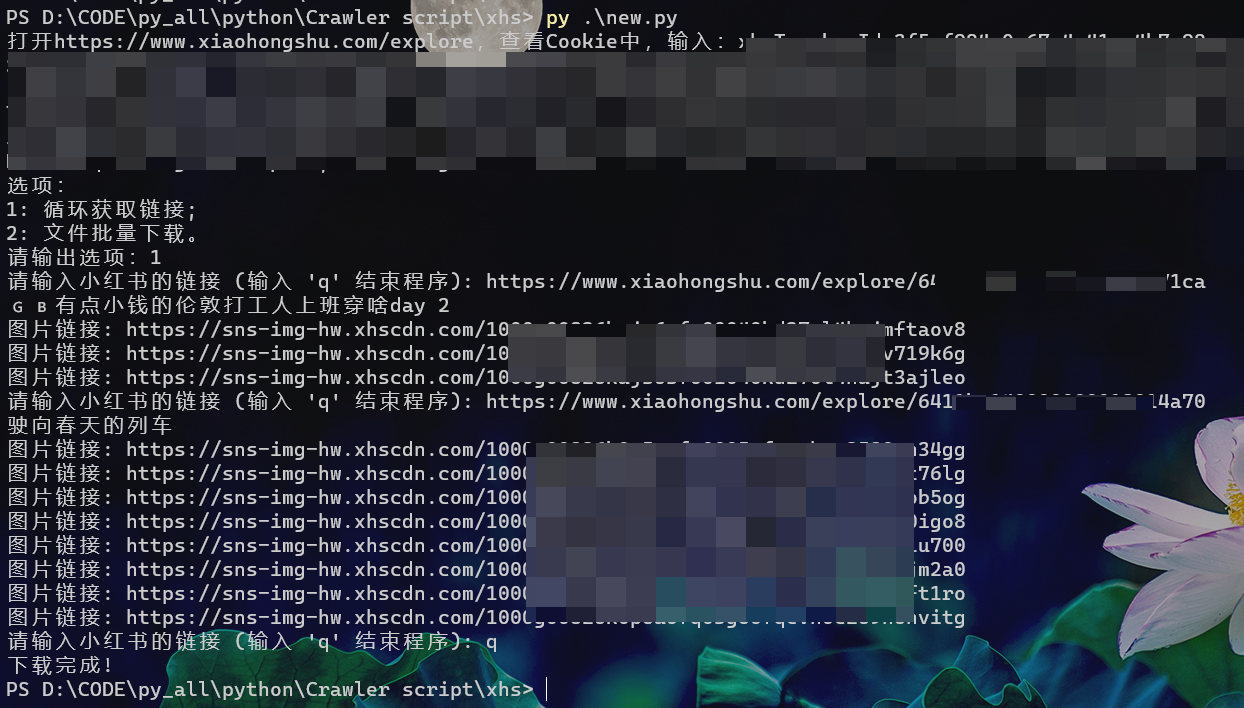
cookie 的获取
f12 开发者工具, 找到 network 或者 网络,f5 刷新页面,翻一下 cookie 很长的就是
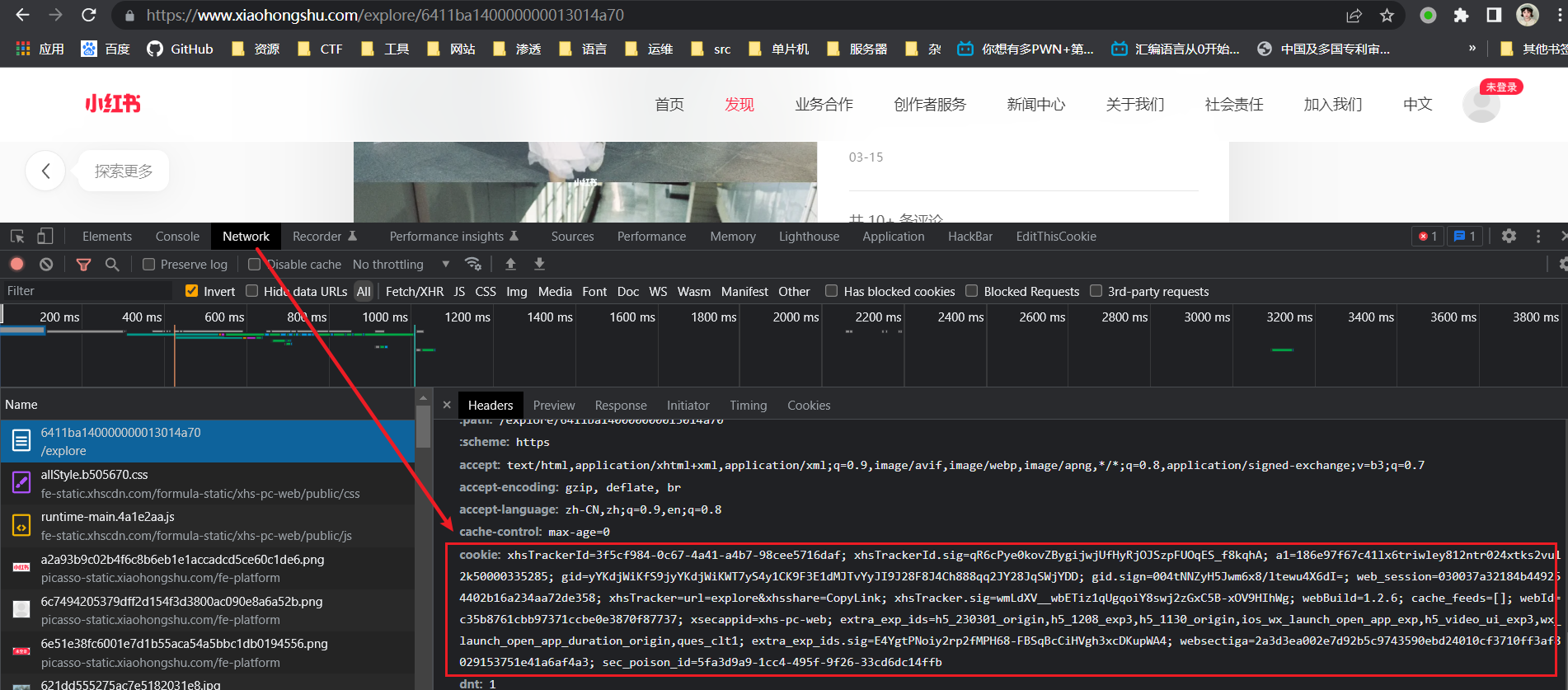
脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
import requests
import re
import json
import time
import shutil
import random
import os
from bs4 import BeautifulSoup
def main(url):
headers = {
'Cookie': f'{COOKIE_EDIT}',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36',
}
htmlData = requests.get(url=url,headers=headers,allow_redirects=True,timeout=10).content.decode('utf-8')
# print(htmlData)
soup = BeautifulSoup(htmlData,"html.parser")
imageData = str(soup.select("body script")[1]).replace('</script>','').replace('<script>window.__INITIAL_STATE__=','').replace('undefined', '"null"')
# print(json.loads(imageData))
imageJson = json.loads(imageData)
# print(imageJson)
# ["note"]["note"]["type"] 视频
note = imageJson["note"]["note"]
# print(note)
# if imageJson["note"]["note"]["type"] == 'video':
# getVideoUri(note)
getImageUri(note)
def PathDecide(directory):
if not os.path.exists(directory):
os.makedirs(directory)
def Download(url, filename):
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36',
}
with requests.get(url,headers=header ,stream=True) as r:
with open(filename, "wb") as f:
shutil.copyfileobj(r.raw, f)
def getImageUri(data):
# print(data)
forepart_url = "https://sns-img-hw.xhscdn.com/"
title = data['title']
print(title)
path = './' + title + '/'
PathDecide(path)
for i in data['imageList']:
traceId = i['traceId']
imageurl = forepart_url + traceId
filepath = path + traceId + '.jpeg' # 全部保存为 jpeg
print("图片链接:",imageurl)
Download(imageurl,filepath)
time.sleep(1)
def getVideoUri(data):
# ["note"]["note"]["desc"] 标题
pass
if __name__ == "__main__":
COOKIE_EDIT = input("打开https://www.xiaohongshu.com/explore,查看Cookie中,输入:").split('\n')
select = input("选项:\n1: 循环获取链接; \n2: 文件批量下载。\n请输出选项:")
if select == '1':
while True:
links = input("请输入小红书的链接 (输入 'q' 结束程序): ")
if links == 'q':
break
main(links)
elif select == '2':
file_path = input("请输入文本文件地址: ")
with open(file_path, 'r') as f:
links = f.read().splitlines()
for link in links:
main(link)
print("下载完成!")
本文由作者按照 CC BY 4.0 进行授权