职教云mooc
职教云mooc
代码原理
在一开始想写的是用户输入配置账号密码就能全自动的是看课程,发现到后面mainContent框架的目录的时候,xpath执行有点问题,目录点击没有好的方法。
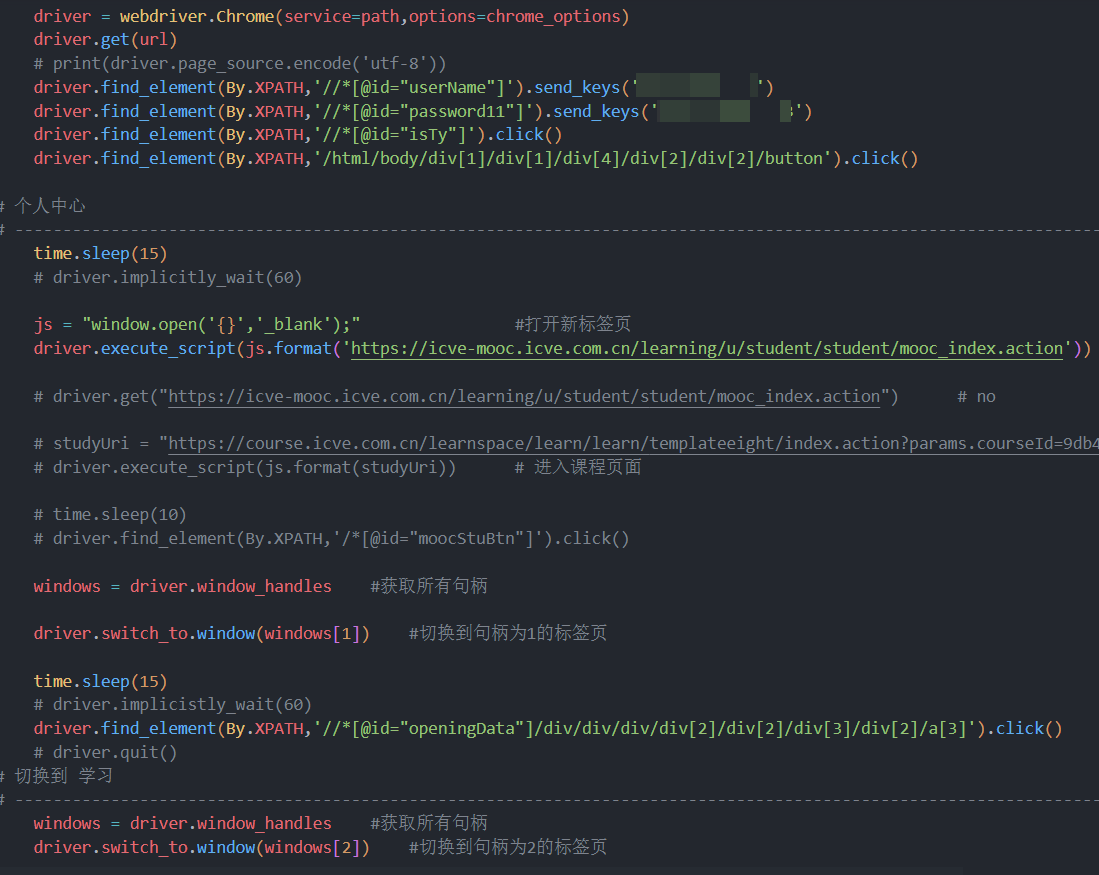
随后,想的是直接通过发包,进行刷课,几个关键包的数据都是js生成,js分析不太会,自己对session和cookie的处理还不太行,返回包的 set-cookie 让我头疼,懒得处理。只能回到老路子

之后又是修修改改,直接使用用户数据;课程是可以单独打开的,这里没有继续抓怕查看有没有计时了,直接,开一半网页,进行课程时长的增加;
也不通过登录点击的方式进行 课程id的获取,直接简单一点,通过保存框架文件的方式进行读取。
这样代码就相对简短,难度下降
后面也没有去判断,这个视频是否看过等,等待的时间都是视频原长度。简单一点
使用方法
安装 google chrome,最好为全用户安装
之后参考 selenuim自动化调用Chrome的两种方法 方法二,放置驱动。
安装python3及pip3模块
1
2
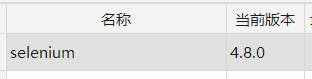
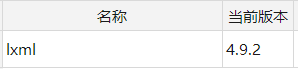
pip3 install selenium
pip3 install lxml
- 新建一个文件夹存放脚本,同时新建一个chrome文件夹(可自定义)用于存放用户数据
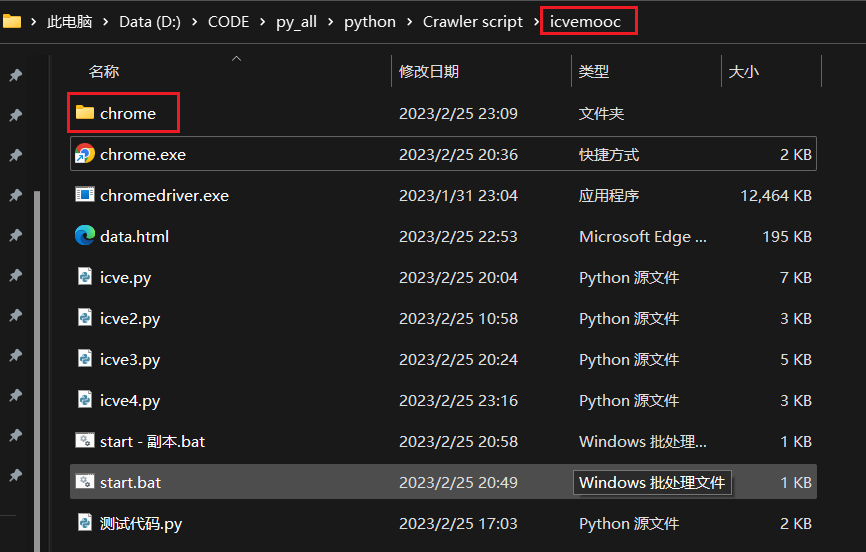
- 新建一个 start.bat
1
2
3
cd /d "C:\Program Files\Google\Chrome\Application\"
chrome.exe --remote-debugging-port=9999 --user-data-dir="D:\CODE\py_all\python\Crawler script\icvemooc\chrome"
pause
第一行,是chrome的安装位置,chrome.exe 的所在位置
第二行,后面的 –user-data-dir= 路径,路径是你 新建的 存放用户数据的位置
- 点击运行 start.bat ,会打开一个chrome窗口,https://icve-mooc.icve.com.cn/cms/ 我们进行登录,点击 我的MOOC,之后在点击课程学习

这个样子就行,里面点击暂停就好,挂着
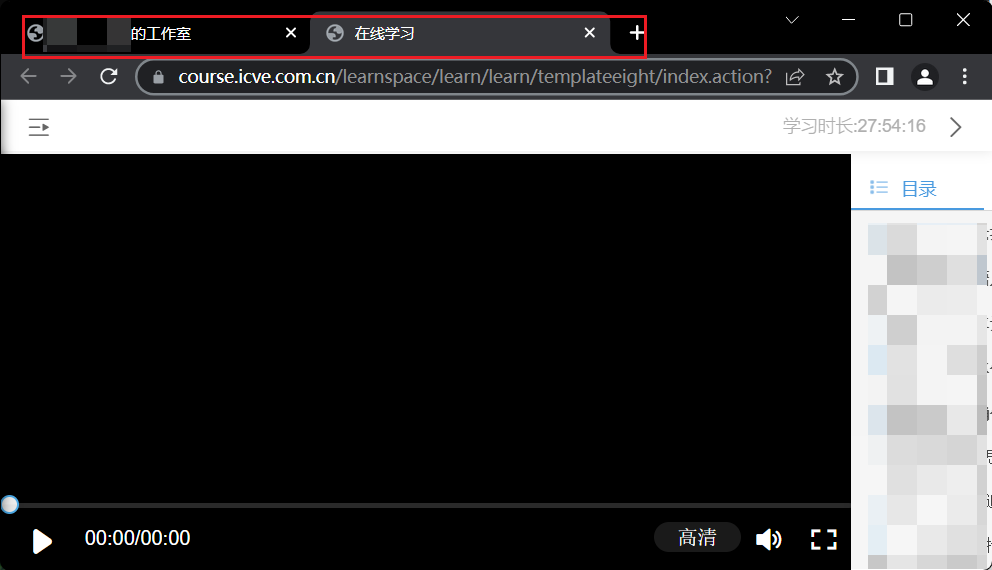
- 我们到目录这边,右键,点击 查看框架源代码
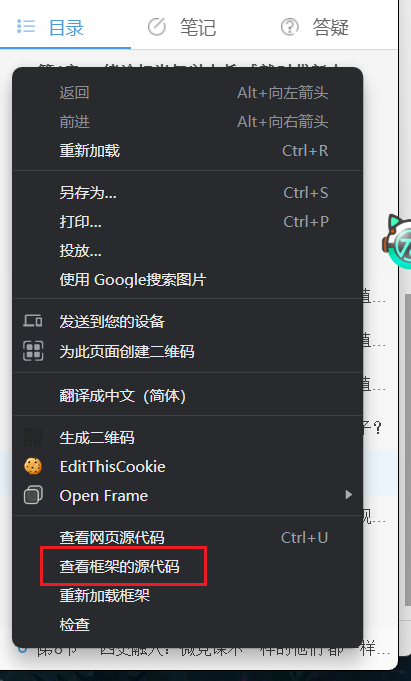
到这里,我们 CTRL+A 全选,然后 CTRL+C 复制,到我们的脚本的目录,保存为 data.html。
也可以保存为其他文件名,如:1.txt 等都可以,要修改代码中的文件名


注意:到这里的时候,通过 start.bat 打开的窗口不要关掉,一直放着,然后我们启动我们的python脚本
他会自己静音和播放,几个窗口都不要关掉
脚本刚刚写出来,有一些还不全面,提示等不够好,如果有问题,请联系我。
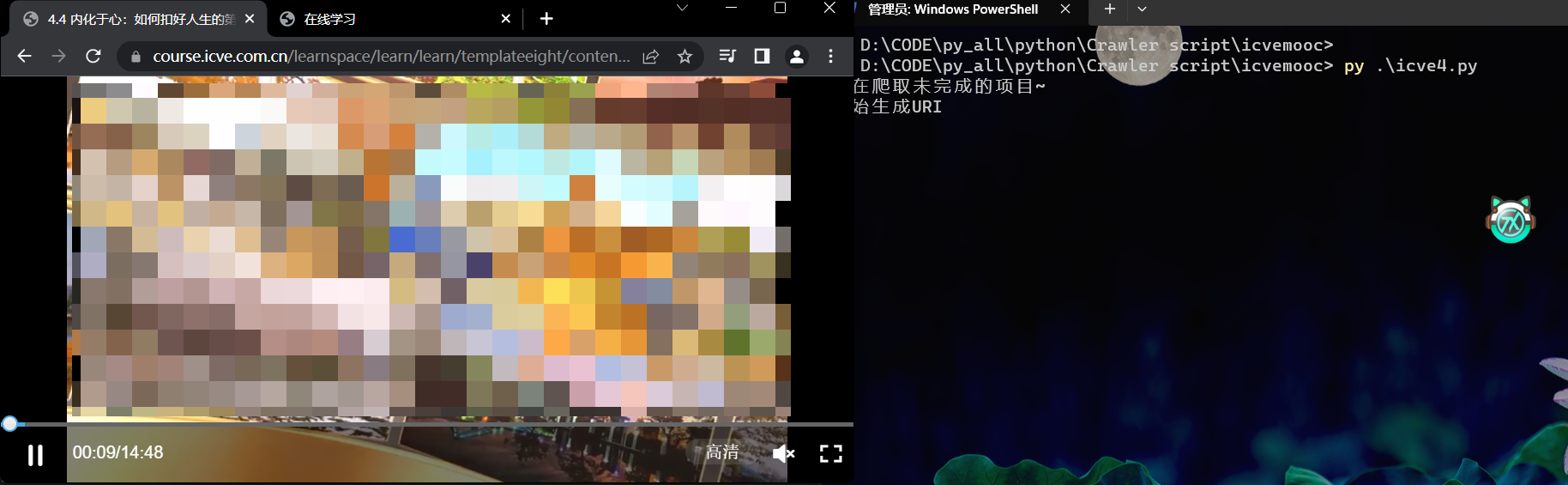
如果出现错误,停止运行。请到《在线学习》处刷新,重新保存框架源代码。
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
from selenium.webdriver.common.by import By
from selenium import webdriver
from lxml import etree
import time
def main():
# global driver
try:
chrome_options = webdriver.ChromeOptions()
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9999")
driver = webdriver.Chrome(options=chrome_options)
except:
exit("Chrome 连接失败,请检查 Chrome 运行情况")
try:
html = open("data.html", "r", encoding="utf-8").read()
html = etree.HTML(html)
except:
exit("data.html 存在问题,请检查 html 文件")
currentCourseId = html.xpath('//input[@type="hidden"][@id="currentCourseId"]/@value')[0]
all_unfinshed_obj = html.xpath("//div[@class='item_done_icon item_done_pos']/..")
unfinshed_obj_xpath_list = get_unfinished_item(all_unfinshed_obj)
urlAll = CreateURI(currentCourseId,unfinshed_obj_xpath_list)
for i, url in enumerate(urlAll):
while True:
try:
print("当前进行第",i+1,"/",len(urlAll))
ask_url(driver, url)
break # 如果执行成功,跳出循环
except:
print(f"重新加载视频,当前是第{i+1}个URL: {url}")
continue # 如果执行失败,重新执行循环
def ask_url(driver,url):
driver.get(url)
print("进行下一节课程:",url)
time.sleep(10)
time.sleep(video_check(driver,url) + 3)
# 获取 视频时间 及 进行 禁音和播放
def video_check(driver,url):
if "video" in url:
xpath = "//span[@id='screen_player_time_2']//text()"
else:
return 0
print("准备开始播放....")
driver.find_element(By.XPATH, '//*[@id="player_pause"]').click()
time.sleep(1)
driver.find_element(By.XPATH, '//*[@id="volumeIcon"]').click()
time.sleep(1)
html = driver.page_source
tree = etree.HTML(html)
length = tree.xpath(xpath)[0]
H_M_S = [int(i) for i in length.split(":")]
if len(H_M_S) == 3:
slp_time = int(H_M_S[0]) * 60 * 60 + int(H_M_S[1]) * 60 + int(H_M_S[2])
print("时长",slp_time)
return slp_time
elif len(H_M_S) == 2:
slp_time = int(H_M_S[0]) * 60 + int(H_M_S[1])
print("时长",slp_time)
return slp_time
def get_unfinished_item(obj):
print("正在爬取未完成的项目")
unfinished_ids = []
for i in obj:
t = i.xpath("div[2]/@class='s_learn_type s_learn_doc'")
if t:
unfinished_ids.append(("doc",i.xpath("./@id")[0].replace("s_point_", "")))
t = i.xpath("div[2]/@class='s_learn_type s_learn_video'")
if t:
unfinished_ids.append(("video",i.xpath("./@id")[0].replace("s_point_", "")))
# print(unfinished_ids)
return unfinished_ids
def CreateURI(courseId,unfinshed_obj_xpath_list):
print("开始生成URI")
uri_list = []
for item in unfinshed_obj_xpath_list:
uriType = item[0]
itemID = item[1]
v_u = 'https://course.icve.com.cn/learnspace/learn/learn/templateeight/content_%s.action?params.courseId=%s¶ms.itemId=%s¶ms.templateStyleType=0&_t=%s'%(uriType,courseId,itemID,str(round(time.time() * 1000)))
# print(v_u)
uri_list.append(v_u)
print("生成完成!")
return uri_list
if __name__ == "__main__":
main()
本文由作者按照 CC BY 4.0 进行授权