Python 百度图片爬取练手
首先,从访问开始进行抓包,分析数据流量。
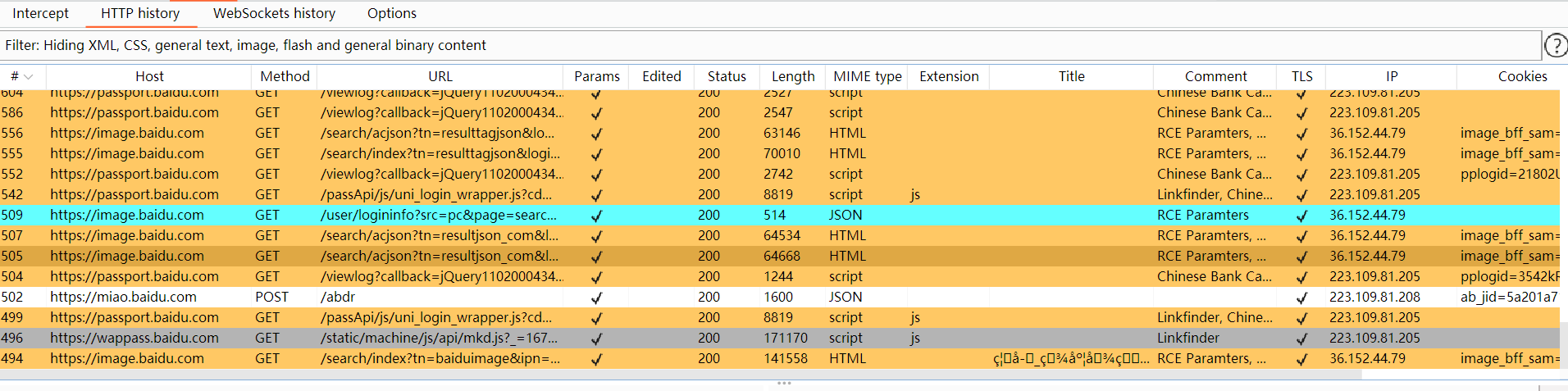
会发现一个html包,但是里面是json数据,是关于图片信息的,里面包含图片URL。就可以开始写脚本了。
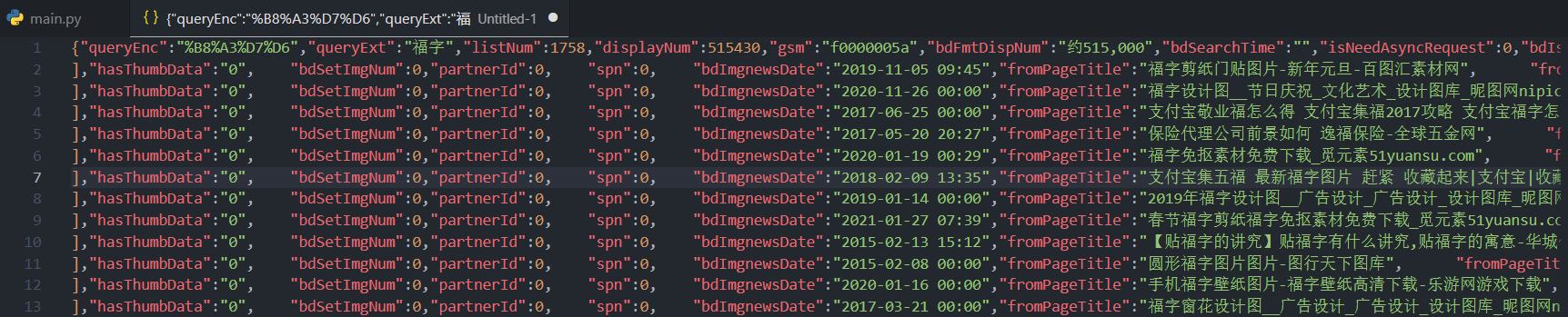
爬取很多的话,可以写一个 sleep,防止短时间访问过多。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
import requests
from urllib.parse import quote
import json
import os
import time
def main():
ipt = input("输入关键字: ")
unipt = quote(ipt)
save_path = './'+ipt+'/'
get_sharpness = input("是否为高清图片(baidu默认分类,不一定存在高清图片)\n1为是,0为否: ")
start_page = input("你想爬取第几页到第几页?一页为30张图片\n请输入开始爬取的页数: ")
stop_page = input("请输入停止爬取的页数: ")
if os.path.exists(save_path) == False:
os.makedirs(save_path)
for page in range(int(start_page),int(stop_page)+1):
if get_sharpness == "1":
url = "http://image.baidu.com/search/acjson?tn=resultjson_com&logid=9045298986494012679&ipn=rj&ct=201326592&is=&fp=result&fr=&word={0}&queryWord={0}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=%252C&ic=&hd=1&latest=0©right=0&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&expermode=&nojc=&isAsync=&pn={1}&rn=30&gsm=3c&1673768924598=".format(unipt,page*30)
Crawler(url,save_path)
else:
url = "http://image.baidu.com/search/acjson?tn=resultjson_com&logid=9028068127247499828&ipn=rj&ct=201326592&is=&fp=result&fr=&word={0}&queryWord={0}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&expermode=&nojc=&isAsync=&pn={1}&rn=30&gsm=f0000003c&1673766662186=".format(unipt,page*30)
Crawler(url,save_path)
print("爬取结束!")
def Crawler(Cu,Cp):
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:108.0) Gecko/20100101 Firefox/108.0"
}
r = requests.get(url=Cu,headers=header)
# r.json()
json_data = json.loads(r.text)
image_num = json_data['bdFmtDispNum']
print("相关图片量"+image_num)
data_list = json_data['data']
image_name = int(time.time())
number = 1
for data in data_list[:-1]:
image_title = data['fromPageTitle']
image_url = data['middleURL']
url_data = requests.get(url=image_url,headers=header).content
f = open(Cp+str(image_name)+'_'+str(number)+'.jpg',"wb")
f.write(url_data)
f.close()
print('[+]',image_title,image_url)
number += 1
if __name__ == "__main__":
main()
运行效果图:
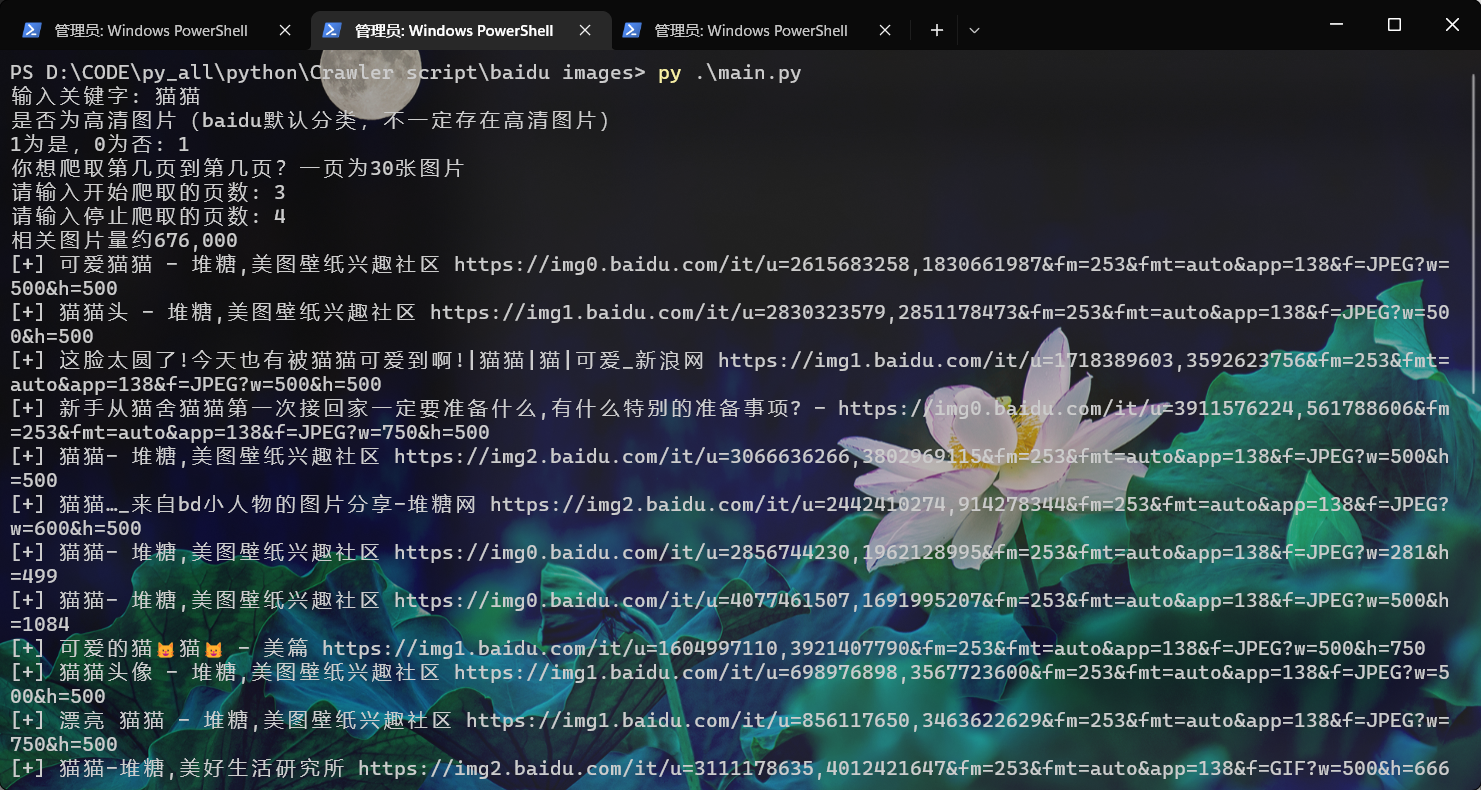
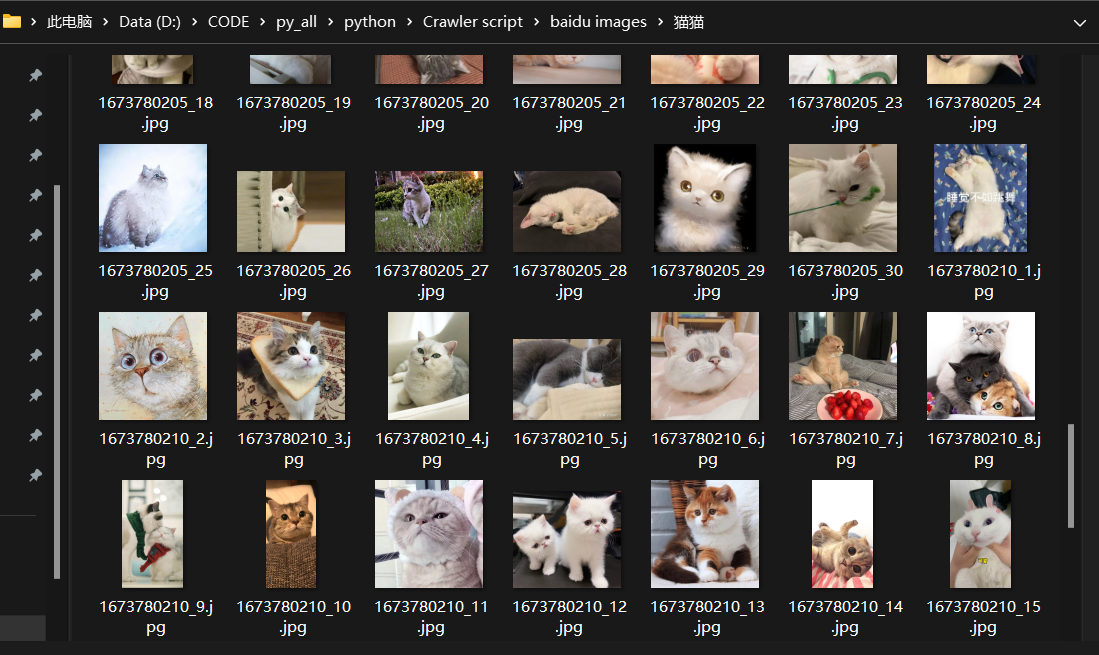
结果:
本文由作者按照 CC BY 4.0 进行授权